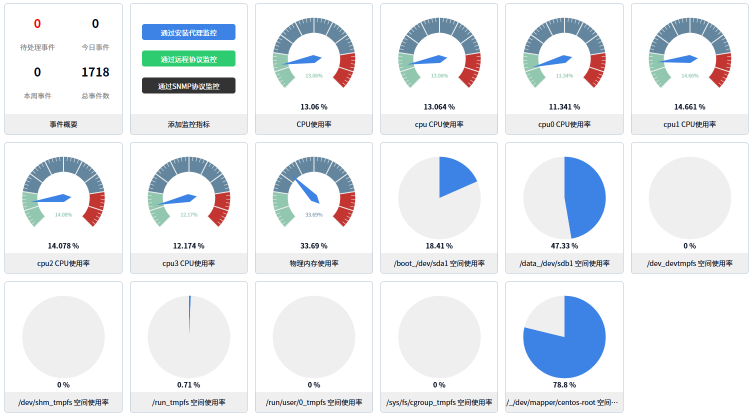
CentOS系统性能监控
CentOS系统监控:包括CPU使用率、内存使用率、磁盘空间使用、磁盘IO、网卡流量、进程CPU使用率
在企业IT运维中,CentOS作为一款广泛使用的Linux服务器操作系统,承担着大量关键业务系统的运行任务。为了保障系统的稳定性和高效性,日常的性能监控是不可或缺的运维工作。通过对系统关键指标的实时监控和分析,可以及时发现潜在问题、优化资源配置、提升系统可用性。
作用与意义:
CPU是服务器的核心资源之一,其使用率直接反映了系统的负载情况。高CPU使用率可能意味着系统正在处理大量任务,也可能表示存在性能瓶颈或资源浪费。
建议阀值:
注意事项:
建议结合系统负载(Load Average)进行综合分析,避免仅以CPU使用率作为判断依据。
作用与意义:
内存是系统运行时的临时存储资源,内存使用率过高可能导致系统频繁进行页面交换(Swapping),从而影响性能。合理的内存管理有助于提升系统响应速度和稳定性。
建议阀值:
注意事项:
建议结合系统内存分配策略(如使用/proc/meminfo或free -h命令)进行分析,避免误判。
作用与意义:
磁盘空间是存储系统数据和日志的关键资源,磁盘空间不足可能导致服务异常甚至系统崩溃。监控磁盘使用情况有助于提前发现存储瓶颈。
建议阀值:
注意事项:
建议定期清理日志、缓存和临时文件,同时结合磁盘使用趋势分析进行容量规划。
作用与意义:
磁盘IO性能直接影响数据读写效率。高IO延迟可能导致数据库响应变慢、应用响应延迟,影响用户体验。
建议阀值:
注意事项:
建议使用工具如iostat、iotop或dstat进行实时监控,结合系统负载分析磁盘性能。
作用与意义:
网络流量是衡量系统通信效率的重要指标。异常的流量波动可能意味着安全威胁、服务异常或带宽瓶颈。
建议阀值:
注意事项:
建议结合网络监控工具(如iftop、nload)进行实时分析,并配合防火墙规则和流量监控策略。
作用与意义:
进程级别的资源使用情况有助于识别异常进程或资源占用过高的服务,是系统性能调优的重要依据。
建议阀值:
注意事项:
建议使用top、htop、ps等工具进行实时监控,并结合进程日志分析其行为。
作用与意义:
日志是系统运行状态的重要记录,有助于排查故障、分析性能瓶颈和安全事件。
建议阀值:
注意事项:
建议使用日志管理工具(如rsyslog、logrotate)进行日志归档和清理,同时结合日志分析工具进行集中监控。
在CentOS系统的运维管理中,对关键性能指标的监控是保障系统稳定运行的基础。通过合理设置监控阀值、结合实际业务负载进行调整,可以有效提升系统的可用性和响应效率。IT运维人员应根据具体业务场景和系统架构,灵活运用监控工具和分析手段,实现精细化、智能化的运维管理。
注: 本文所列阀值仅供参考,实际运维中应根据具体业务需求、硬件配置及系统负载进行调整。建议结合监控工具(如SUM服务器事件管理软件等)进行实时监控与告警设置,以提升运维效率和系统可靠性。