


DeepSeek是杭州深度求索人工智能基础技术研究有限公司训练的LLM(大语言模型),现阶段其大模型主要有:DeepSeek-R1和DeepSeek-R1-Zero。DeepSeek-R1在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,较大提升了模型推理能力。在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版。开源 DeepSeek-R1-Zero 和 DeepSeek-R1 两个 660B 模型的同时,通过 DeepSeek-R1 的输出,蒸馏了 6 个小模型开源给社区,其中 32B 和 70B 模型在多项能力上实现了对标 OpenAI o1-mini 的效果。
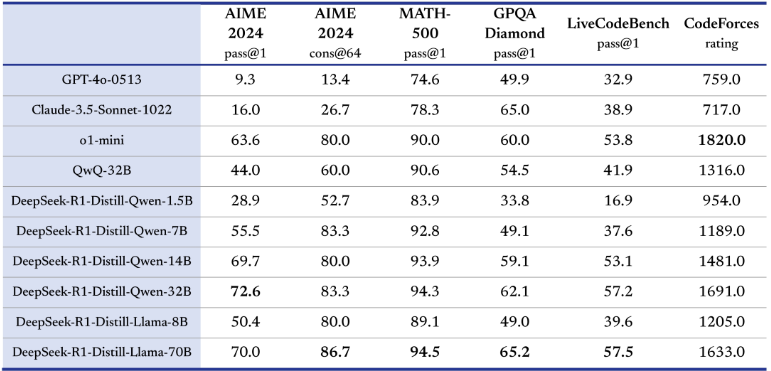
此图来源于DeepSeek官方网站
DeepSeek其大模型采用宽松的MIT许可开源,不限制商用,使用不需申请。但同时,DeepSeek公司还提供网页版实时对话、APP版实时对话以及API调用对话等多种使用途径。
DeekSeek API版为收费调用,按Tokens计费。
Token 用量计算
token 是模型用来表示自然语言文本的基本单位,也是我们的计费单元,可以直观的理解为“字”或“词”;通常 1 个中文词语、1 个英文单词、1 个数字或 1 个符号计为 1 个 token。
一般情况下模型中 token 和字数的换算比例大致如下:
1 个英文字符 ≈ 0.3 个 token。
1 个中文字符 ≈ 0.6 个 token。
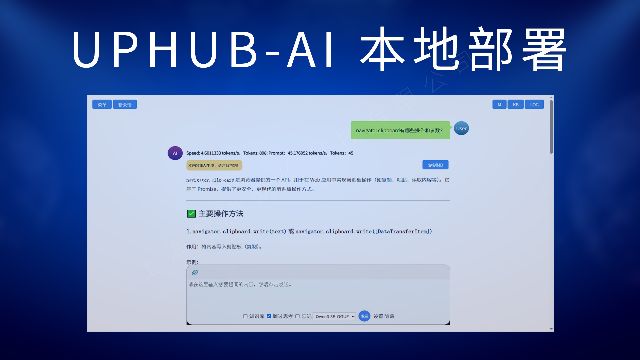
开源DeepSeek个人部署
DeekSeek是开源的大模型,可以通过llama.cpp、ollama等量化推理程序在低配置的电脑、主机上运行。从而实现个人部署,满足个人或公司日常的AI需求。
对有需要的可以点击以下连接进入DeepSeek的官网进一步了解。