基于RAG(检索增强生成)生成式AI优化方法,在UpHub AI中实现企业或个人知识库,不需要微调大模型
在人工智能领域,检索增强生成 (Retrieval-Augmented Generation, RAG) 是一种日益流行的生成式AI高质量回答的优化技术,它结合了检索模型和生成模型的优势,为语言模型带来了更准确、更可靠的答案生成能力。同时,Embedding模型在RAG系统中扮演着至关重要的角色,其选择直接影响着RAG系统的关键性能和质量。本文将深入探讨RAG的工作流程与原理,详细介绍Embedding模型及其选择策略,帮助企业或个人全面理解RAG系统和Embedding模型。
下载本地大模型部署推理软件UpHub AI,请点击这里。
一、什么是RAG?
RAG并非一种全新的模型架构,而是一种将现有模型进行组合和优化的方法。传统的大语言模型(LLM)在回答问题时,主要依赖于其训练数据中的知识。虽然这些模型拥有庞大的参数量和强大的学习能力,但它们仍然存在一些局限性:
- 知识更新缓慢: LLM的训练成本高昂,知识更新需要重新训练整个模型,效率低下。
- 幻觉问题: LLM有时会生成虚假或不准确的信息,即所谓的“幻觉”。
- 缺乏可解释性: LLM的决策过程难以追踪,难以解释其答案的来源。
RAG应运而生,旨在解决这些问题。RAG的核心思想是:在生成答案之前,先从外部知识库中检索相关信息,然后将这些信息作为上下文提供给LLM,让LLM基于检索到的信息生成答案。 这样,LLM就可以利用外部知识库的新信息,减少幻觉,并提供更具可解释性的答案。
二、RAG的工作流程与原理
RAG的工作流程通常包含以下几个关键步骤:
- 用户提问: 用户向RAG系统提出问题。
- 问题理解与检索: RAG系统首先需要理解用户的问题,并将其转化为适合检索的查询。通常使用Embedding模型将问题编码成向量表示。
- 知识库检索: 将查询向量与知识库中的文档向量进行比较,找到相关的文档。常用的相似度计算方法包括余弦相似度、点积等。
- 上下文构建: 将检索到的相关文档与原始问题组合成一个包含上下文的提示(Prompt)。
- 答案生成: 将构建好的提示输入到LLM中,LLM基于提示中的问题和上下文信息生成答案。
原理:
RAG的原理可以概括为以下几点:
- 检索增强: 通过检索外部知识库,为LLM提供额外的上下文信息,弥补LLM知识的不足。
- 上下文学习: LLM在生成答案时,不仅考虑自身已有的知识,还参考检索到的上下文信息,提高答案的准确性和相关性。
- 可追溯性: 由于答案是基于检索到的文档生成的,因此可以追溯答案的来源,提高可信度。
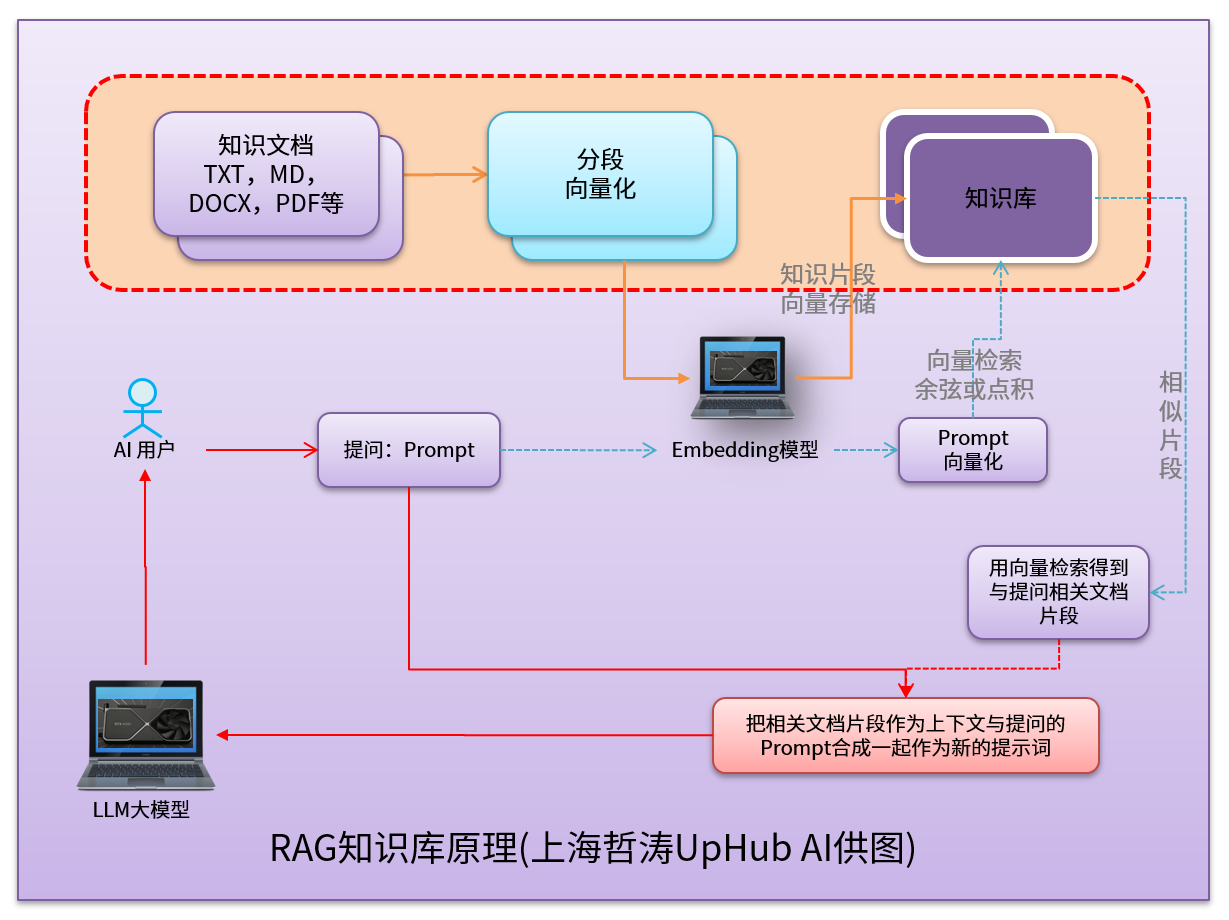
RAG知识库原理图
三、什么是Embedding模型?
Embedding模型是一种将文本、图像、音频等数据映射到高维向量空间的技术。在RAG系统中,Embedding模型用于将问题和文档编码成向量表示,以便进行相似度计算和检索。
Embedding模型的作用:
- 语义表示: 将文本的语义信息编码到向量中,使得语义相似的文本在向量空间中距离更近。
- 相似度计算: 通过计算向量之间的距离或相似度,判断两个文本之间的相关性。
- 高效检索: 利用向量索引技术,快速找到与查询向量相似的文档。
常见的Embedding模型:
- nomic-embed-text(开源): 这是一个通用的文本Embedding模型,在英文文本上表现良好。
- bge-m3(开源): 这是一个多语言Embedding模型,支持100多种语言,适用于处理不同语言的文本。
- bge-large-zh-v1.5(开源): 这是一个基于bge-m3微调的中文Embedding模型,在中文文本上表现更佳。
- Sentence Transformers(开源): 这是一个流行的开源Embedding模型库,提供了多种预训练模型,例如all-MiniLM-L6-v2、all-mpnet-base-v2等。
- OpenAI Embeddings: OpenAI提供了一系列Embedding模型,例如text-embedding-ada-002,具有良好的性能和易用性。
四、Embedding模型的选择直接决定RAG系统质量
Embedding模型的选择直接影响着RAG系统的检索效率和答案质量。一个好的Embedding模型应该具备以下特点:
- 语义相关性: 能够准确捕捉文本的语义信息,使得语义相似的文本在向量空间中距离更近。
- 泛化能力: 能够在不同领域和任务上表现良好,避免过度拟合特定数据集。
- 计算效率: 能够快速生成向量表示,提高检索效率。
- 支持的语言: 能够支持RAG系统所处理的语言。
Embedding模型选择的策略:
- 考虑知识库的语言: 如果知识库主要包含中文文档,则应选择中文Embedding模型,例如bge-large-zh-v1.5。如果知识库包含多种语言的文档,则应选择多语言Embedding模型,例如bge-m3。
- 评估语义相关性: 使用一些评估数据集,例如GLUE、STS等,比较不同Embedding模型在语义相关性方面的表现。
- 考虑计算效率: 在保证语义相关性的前提下,选择计算效率更高的Embedding模型,提高检索效率。
- 进行实验验证: 在RAG系统中集成不同的Embedding模型,并使用实际问题进行测试,比较不同Embedding模型对答案质量的影响。
- 考虑成本: 如果使用商业化的Embedding模型(例如OpenAI Embeddings),需要考虑成本因素。
一些常用的Embedding模型选择参考:
- 英文文本: nomic-embed-text、OpenAI text-embedding-ada-002、Sentence Transformers (all-MiniLM-L6-v2, all-mpnet-base-v2)
- 中文文本: bge-large-zh-v1.5、Sentence Transformers (all-MiniLM-L6-v2, all-mpnet-base-v2)
- 多语言文本: bge-m3、Sentence Transformers (all-MiniLM-L6-v2, all-mpnet-base-v2)
五、在UpHub AI中使用RAG提高AI的生成质量
UpHub AI提供了自主研发的RAG简易存储数据库,系统基于生产者-消费者模式自动对需要知识库的提问进行RAG介入。以提高问题的垂直业务或企业私有文档中的生成能力。以下是在UpHub AI的个人版中使用RAG优化方法的一个示例:
(1) 首页通过RAG分段文档;
(2) 然后把每个分段使用Embedding模型进行向量化;
(3) 在提问时,选择搜索知识库;
(4) 如果在知识库中有相关内容,在生成时就会自动按这些内容生成。

在UpHub AI中使用RAG知识库提供生成质量
六、写在后面
RAG作为一种强大的技术,通过结合检索和生成模型,为LLM带来了更准确、更可靠的答案生成能力。Embedding模型在RAG系统中扮演着关键角色,其选择直接影响着RAG系统的性能。选择合适的Embedding模型需要综合考虑知识库的语言、语义相关性、计算效率和成本等因素。希望本文能够帮助你更好地理解RAG系统和Embedding模型,并在实际应用中做出明智的选择。
未来发展趋势:
- 自适应Embedding模型: 根据不同的问题和文档,自动选择合适的Embedding模型。
- 动态Embedding模型: 根据知识库的更新,动态调整Embedding模型,保持其准确性和有效性。
- 多模态Embedding模型: 将文本、图像、音频等多种模态的信息进行融合,生成更丰富的向量表示。