
Presence Penalty 的含义
“Presence Penalty”(存在惩罚)是一种用于控制 LLM 生成文本多样性的技术。简单来说,它会惩罚模型在生成文本时“过于关注”或“过于强调”当前正在生成的内容。
- 核心思想: LLM 在生成文本时,会倾向于重复使用之前已经出现的词语或短语,以保持连贯性。Presence Penalty 的作用就是打破这种倾向,鼓励模型尝试新的词语和表达方式。
- 具体机制: 模型在生成每个token(单词或子词)时,都会根据其“存在频率”进行评分。 频率越高,表示该token在当前文本中出现次数越多,惩罚值也就越大。 然后,模型会根据这个惩罚值调整选择下一个token的概率。
Presence Penalty (存在惩罚) 是一种用于控制大型语言模型 (LLM) 输出文本多样性的技术。它的核心思想是:对已经出现的token(词语或子词)施加惩罚,鼓励模型生成新的、不同的token。 简单来说,就是让模型“避免重复”。
想象一下,在和LLM聊天,它总是重复使用一些关键词或短语,这会让人觉得很无聊。Presence Penalty 就是为了解决这个问题而设计的。
Presence Penalty 在 LLM 推理和训练中的作用
-
推理(Inference):
- 提高文本多样性: 当你在使用 LLM 生成文本时,可以启用 Presence Penalty 来避免生成过于重复、单调的文本。 它可以让模型尝试不同的表达方式,产生更具创造性和多样性的结果。
- 控制输出风格: 通过调整 Presence Penalty 的值,你可以一定程度上控制输出的风格。 例如,较高的值会鼓励更具实验性的、不寻常的表达;较低的值则会使模型更倾向于保持流畅和自然的语言风格。
-
训练(Training):
- 正则化: 在 LLM 的训练过程中,Presence Penalty 可以作为一种正则化技术,防止模型过度拟合训练数据。 强制模型生成多样化的文本,可以降低模型对特定模式的依赖性,提高泛化能力。
- 引导探索: Presence Penalty 可以引导模型在探索潜在的文本空间时,更积极地尝试新的组合和表达方式。
Presence Penalty 的取值范围
Presence Penalty 的取值范围通常在 0 到2之间。
- 0: 不启用 Presence Penalty,模型会按照其原本的概率分布生成文本,没有惩罚任何已出现的token。
- 0.1 - 0.5: 这是一个比较常用的取值范围。 较高的值(接近 1)会更强烈地惩罚已出现的token,导致文本更加多样化,但也可能导致文本质量下降,变得不连贯或不自然。 较低的值(接近 0)则会使 Presence Penalty 的效果不明显。
- 0.6 - 1.0: 如果需要非常强的多样性,可以尝试更高的值。 但需要小心控制,避免文本质量严重受损。
- 正数 (0 < x <= 2): 表示存在 Presence Penalty,数值越大,惩罚力度越大,模型越倾向于生成新的token。
- 2: 理论上是惩罚值,但实际应用中很少使用,因为会过度限制模型的选择,可能导致文本不流畅或不自然。
取值建议:
- 没有绝对的值: Presence Penalty 的取值取决于具体的应用场景、LLM 的架构、以及你希望达到的效果。
- 实验和调整: 好的方法是进行实验,尝试不同的取值,观察 LLM 生成的文本,并根据实际情况进行调整。
- 结合其他参数: Presence Penalty 通常与其他参数(如 temperature)一起使用,以实现更精细的控制。
| 场景 | Presence Penalty 建议取值 | 说明 |
|---|---|---|
| 写作 (小说、诗歌等) | 0.1 - 0.5 | 需要一定的重复性来保持风格和节奏,但也要避免过度重复。较低的 Presence Penalty 可以让模型在保持风格的同时,引入一些新的元素。 |
| 知识问答 | 0.2 - 0.8 | 知识问答需要准确性和简洁性,避免不必要的重复。适当的 Presence Penalty 可以提高答案的多样性,但也要确保答案的逻辑性和连贯性。 |
| 创意生成 (故事、代码等) | 0.5 - 1.0 | 创意生成需要更多的多样性和新颖性,Presence Penalty 可以鼓励模型探索更多的可能性。 |
| 对话/聊天 | 0.3 - 0.7 | 对话需要自然流畅,避免过于生硬的“避免重复”效果。 |
| 总结/摘要 | 0.1 - 0.4 | 总结需要抓住核心信息,避免过度改变原文的表达方式。较低的 Presence Penalty 可以保持原文的风格和重点。 |
总结
Presence Penalty 是一个强大的工具,可以帮助用户更好地控制 LLM 生成文本的多样性。 掌握它的原理和用法,能够让你更好地利用 LLM 的潜力,创造出更具价值的文本内容。
- 没有一个通用的值: Presence Penalty 的取值取决于具体的任务、数据集和模型。
- 需要实验调整: 应该根据实际情况进行实验,调整 Presence Penalty 的值,找到适合您的应用的设置。
- 与其他参数的交互: Presence Penalty 会与其他参数(例如 Temperature, Top_p)相互作用,需要综合考虑。
在本地部署大模型Deepseek、llama、gemma等时,可以适当调整不同的Presence Penalty 参数,以获得更好的输出。
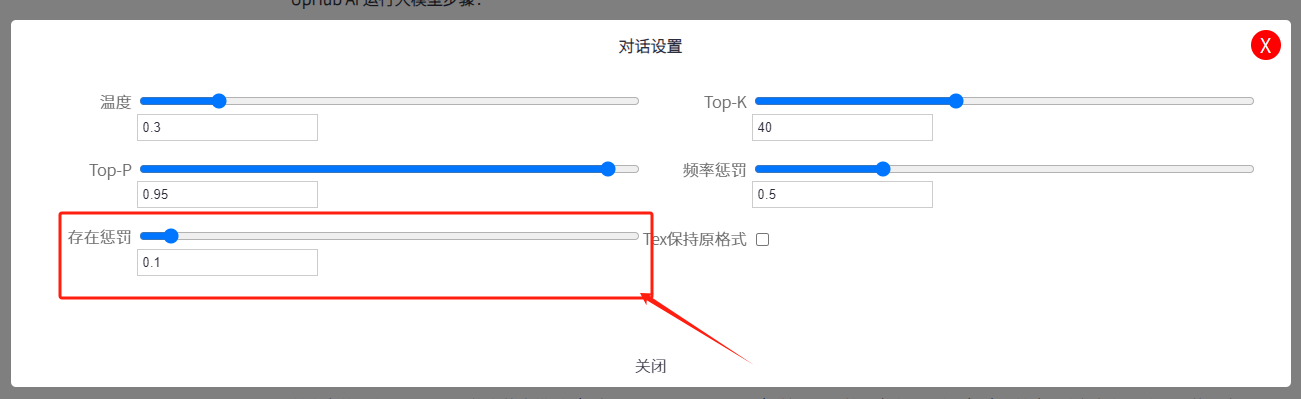
在UpHub AI中如何在对话中设置 Presence Penalty频率惩罚