
频率惩罚 (Frequency Penalty) 的含义
频率惩罚是一种在生成文本时使用的技术,旨在减少模型在生成过程中过度重复某些词语或短语。简单来说,它会降低模型在生成下一个词时,选择已经出现过很多次出现的词的概率。
可以把它想象成一个“惩罚机制”,对频繁出现的词语施加一定的“惩罚”,鼓励模型尝试使用更具多样性的词汇。
频率惩罚在LLM推理或训练中的作用
- 提高文本的多样性: 这是频率惩罚主要的作用。 默认情况下,LLM会倾向于基于它在训练数据中看到多的模式进行预测。 频繁惩罚可以打破这种模式,让模型生成更具创造性和多样性的文本。
- 避免重复和冗余: 在生成长文本时,频率惩罚可以有效避免模型在某些主题或短语上反复出现,从而使文本更流畅、更自然。
- 改善训练效果: 在LLM的训练过程中,频率惩罚可以帮助模型更好地学习到词语之间的关系,并减少对特定词语的过度依赖。
频率惩罚的取值范围
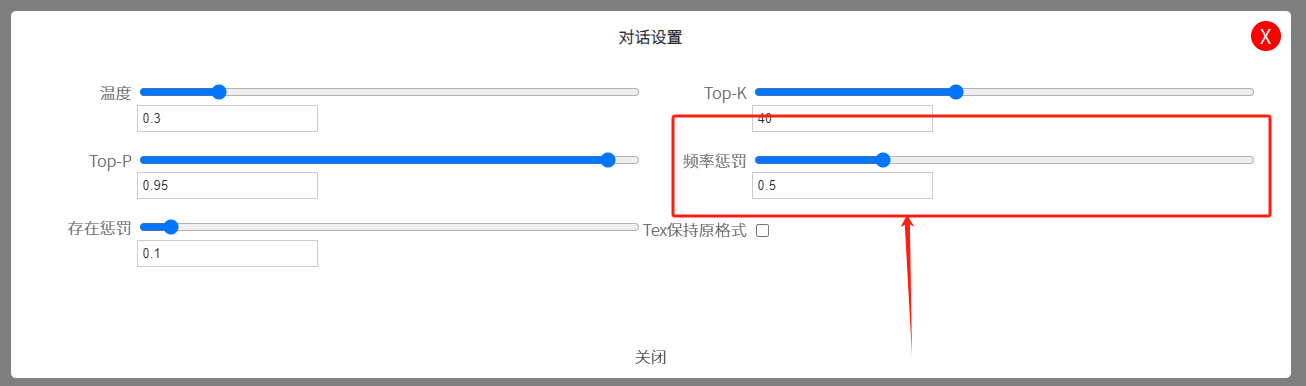
频率惩罚的值通常是一个介于0到2之间的浮点数。
- 0 (或非常接近0): 表示没有频率惩罚。 模型会完全按照其概率分布进行预测,生成文本时不会考虑词语出现的频率。 这种情况下,生成的文本可能比较保守、重复,缺乏多样性。
- 0.1 - 0.5: 这个范围通常适用于大多数写作场景。 较低的值(例如0.1)可以稍微减少重复,但不会过度影响模型的预测。 较高的值(例如0.5)会更强烈地惩罚频繁出现的词语,从而产生更具多样性的文本,但也可能导致模型生成一些不连贯或不自然的句子。
- 0.6 - 1.0: 这个范围通常用于需要非常高多样性的场景,例如创意写作、诗歌生成等。 较高的值会显著降低模型对频繁词语的偏好,但同时也可能增加生成文本的风险,需要谨慎调整。
- 2: 表示非常强的频率惩罚,几乎会阻止模型重复使用已经出现过的词语。
不同场景下的取值建议:
- 写作 (小说、文章): 0.1 - 0.3 通常是一个不错的起点,可以根据具体需求进行调整。
- 对话生成: 0.2 - 0.4 保持对话的自然流畅性很重要,需要适度地控制频率惩罚。
- 知识问答: 0.0 - 0.1 在知识问答中,准确性比多样性更重要,因此频率惩罚应该尽可能小,以确保模型能够准确地回答问题。
- 创意写作 (诗歌、剧本): 0.5 - 1.0 为了鼓励模型生成新颖的表达方式,可以适当提高频率惩罚的值。
| 场景 | Frequency Penalty 取值范围 | 说明 |
|---|---|---|
| 创意写作 (小说、诗歌等) | 0.5 - 1.2 | 需要文本的多样性和创造性,适当的频率惩罚可以避免重复,鼓励模型使用更丰富的词汇。 但过高的惩罚可能会导致文本不连贯或语义不通。 |
| 知识问答/摘要生成 | 0 - 0.5 | 更注重准确性和简洁性,不需要太多的多样性。 较高的频率惩罚可能会影响模型的表达能力,降低答案的质量。 如果发现模型重复使用相同的短语,可以适当提高惩罚值。 |
| 代码生成 | 0 - 0.2 | 代码的准确性比多样性更重要,过高的频率惩罚可能会导致代码逻辑错误。 |
| 对话系统 | 0.3 - 0.8 | 需要在保持对话流畅性的同时避免重复,适当的频率惩罚可以提高对话的质量。 |
| 文本续写 | 0.2 - 1.0 | 需要根据具体情况调整,如果续写的文本需要与原文本保持一致性,则应使用较低的频率惩罚;如果希望续写的内容更加多样化,则可以使用较高的频率惩罚。 |
重要提示:
- 频率惩罚只是LLM生成文本的众多参数之一。 取值取决于具体的任务、模型和数据集。
- 通常需要通过实验来找到适合特定场景的频率惩罚值。
- 除了频率惩罚,还有其他类型的惩罚,例如存在惩罚 (Presence Penalty) 和考据惩罚 (Patience Penalty),它们可以共同用于控制生成文本的多样性和质量。
- 与其他参数的交互: Frequency Penalty 的效果会受到其他参数的影响,例如 Temperature (温度) 和 Top_p (核采样)。 Temperature 控制随机性,Top_p 限制选择的词语范围。
- 实验和调整: 好的 Frequency Penalty 取值取决于具体的任务和数据集。建议您通过实验来找到适合您的场景的值。
- Presence Penalty 的配合: Frequency Penalty 通常与 Presence Penalty 配合使用,Presence Penalty 惩罚任何在文本中出现过的词语,而 Frequency Penalty 则根据词语出现的频率进行惩罚。
在UpHub AI中如何在对话中设置 Frequency Penalty频率惩罚