基于UpHub AI构建高并发的本地化AI大模型部署
AI大模型的本地化部署是企业实现AI推理的重要途径,其主要考量的维度有:隐私、数据安全、物理隔离网络、内网使用AI、ERP系统对接AI大模型、大模型垂直知识微调、RAG知识库等。然后AI大模型的推理是计算资源密集的软件系统,同时还需要各种支撑软件辅助运行,除此之外,高并发是企业部署AI的一个重要需求。所谓并发就是多人同时使用,同时推理。实际上AI进行一个会话时就需要较高硬件资源,大部分建议服务器配置,均是运行AI大模型的基本配置(即进行特定版本的大模型的基本运行),这也是很多企业、单位在部署AI大模型后难以真正使用起来和运行起来的原因,即一开始就按较少要求选择服务器硬件,但又希望运行丝滑、高并发,这显然不切实际。本文从AI大模型的推理运行特点出发,把AI大模型的高并发部署常规点进行介绍,以便企业在选择AI推理硬件资源时,可以有效配置硬件环境和要求,进而做到有的放矢。
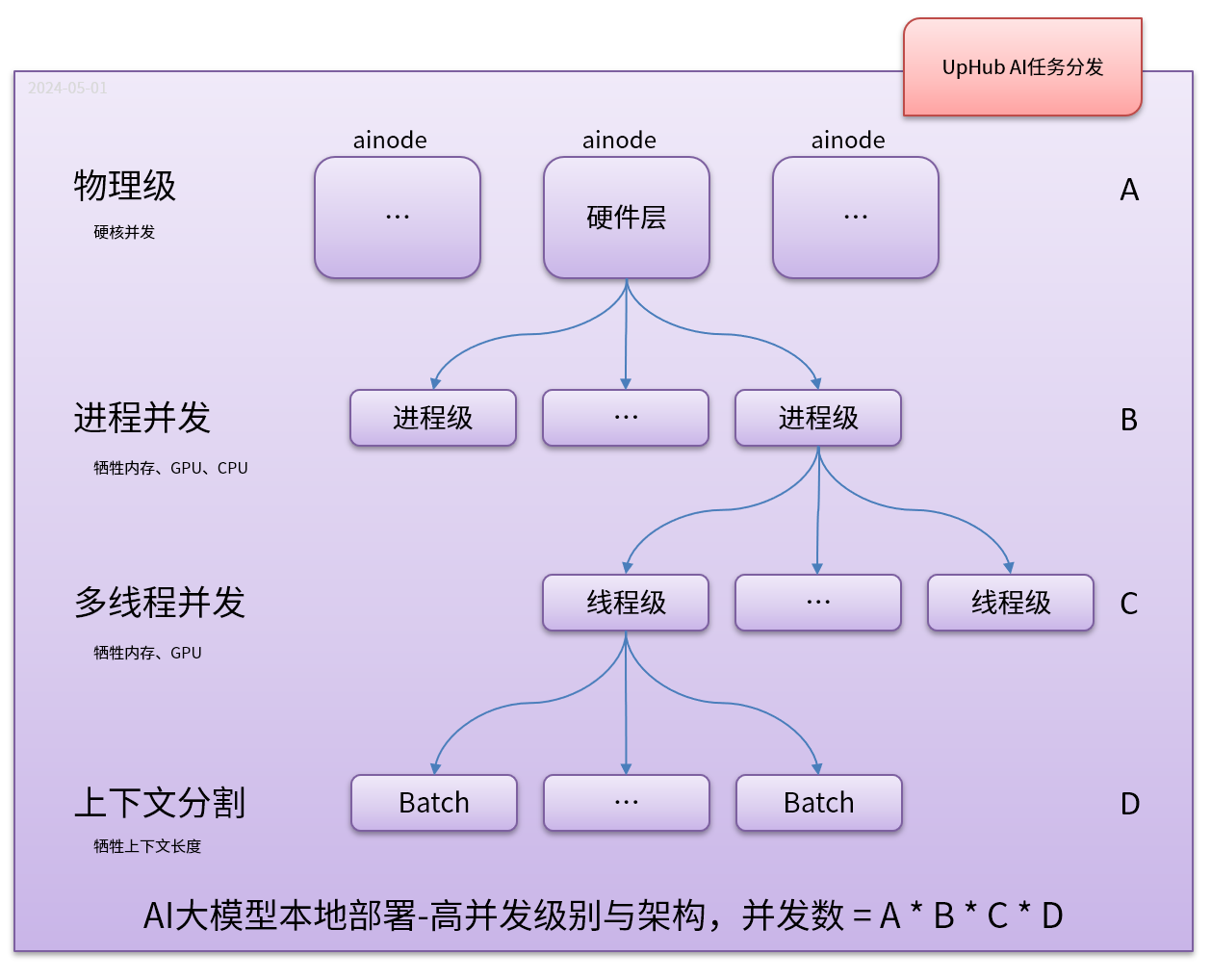
AI大模型并发主要可以在以下层级中进行考虑:
(1) 物理层:即采用增加物理服务器来实现真正的并发,这是AI大模型物理并发的重要有段,比如,1台服务器配置可以同时进行1个推理,那么2台就可以同时进行2个推理,这是易于理解的;
(2) 进程级别:即在一台物理设备上运行多个推理程序,这就在一定程度上要求硬件资源充足(特别是内存、CPU、GPU),实现硬件资源在进程级别的分配;
(3) 线程级别:即在一个进程中,给同一个大模型启用多个线程同时进行推理,同进程,显然这也是需要更多的内存、CPU、GPU。但这里面要共享一部分模型数据,节省内存;
(4) 上下文切割级别(batch):这也是目前广泛使用的并行方式,但这不是真正的并行,它是在牺牲上下文长度换来的模拟并发。比如:Deepseek上下文有128K,如果采用8个并行,则每个并行的上下文为:128/8=16K,16K在一推的对话和推理也是足够的。上下文切割并行,通常就是满载全部上下文所需要的资源,这可以解决一部分资源紧张的问题。目前开源推理程序均具有这个级别的并行,比如:llama.cpp、vLLM、turnllama.cpp(基于llama.cpp)等。
UpHub AI使用生产者和消费者模式,它的本质是一个任务-工具管理软件,并不直接进行AI大模型推理。它的后端可以对接AI大模型推理,实现AI任务的处理。因为UpHub AI使用的是生产者和消费者模式,它主要进行任务分发、管理、调度,进而可以自动实现与后端的AI推理进行无编程对接。即AI推理只是一个任务消费者,既然是消费者,那它就可以无限扩展,只要有预算,企业可以不断增加这样的消费者实现AI任务的处理,显然这里不限于AI任务的处理,它同时还可以任何任务。在高并发部署中,UpHub AI可以有效与后端物理层(多台推理服务器)、进程级别推理消费者、线程级推理消费者、上下文切割级别(batch)级的消费者实现无缝对接。
主流推理系统,比如:llama.cpp、vLLM等,可以混合作为UpHub AI的后端推理程序,并且无需过多编程(实际上我们已经实现了turnllama.cpp、turnllm.python(vLLM)),来在llama.cpp和vLLM中实现消费者模式。在UpHub AI中所有模型可使用统一的推理界面、配置界面、对话界面,无需关心它现在是在哪里运行以及如何运行。
在实际部署中,常购的开源大模型本地部署主要有:Deepseek-R1, 7B, 8B, 14B, 32B, 70B, 671B;多模态开源大模型有:Gemma3 4B, 12B , 27B等。